The Discovery Factory
A repeatable method for building predictive systems you can actually trust — one that augments an expert today and earns the right to act on its own tomorrow.
Signals, not models, are the bottleneck.
Everyone building with AI eventually hits the same wall: the model is sophisticated, and the results are a coin flip.
The instinct is to reach for a bigger model. Usually that’s the wrong move.
The bottleneck is almost never the model. It’s the inputs. A brilliant model fed weak signals gives confident, wrong answers. The model isn’t broken — it’s starved.
The Universal Problem
Across wildly different fields — forecasting weather, planning data-center capacity, managing inventory, dispatching a power grid, predicting machine failure — the same failure repeats. Organizations invest heavily in the model and treat the inputs as a solved problem. They are not.
The diagnosis is almost always the same: the model is being asked to predict an outcome from signals that don’t carry enough information about it. Swapping algorithms barely helps. Adding more data barely helps. The real question isn’t “what model should we use?” It is: which signals actually predict the outcome — and how do we find them, prove them, and feed them to the machine without fooling ourselves?
The Method at a Glance
Inputs, Not the Model
The single insight that reorganizes the whole effort: the bottleneck in machine-driven decisions is rarely the model. It is the quality of the inputs the model learns from. A few consequences follow, and they hold in every domain.
The Whole Method in One Picture
From a flood of weak signals to a few validated ones — screened by engines, judged by a human + AI middle, and promoted up a trust ladder before anything acts on its own.
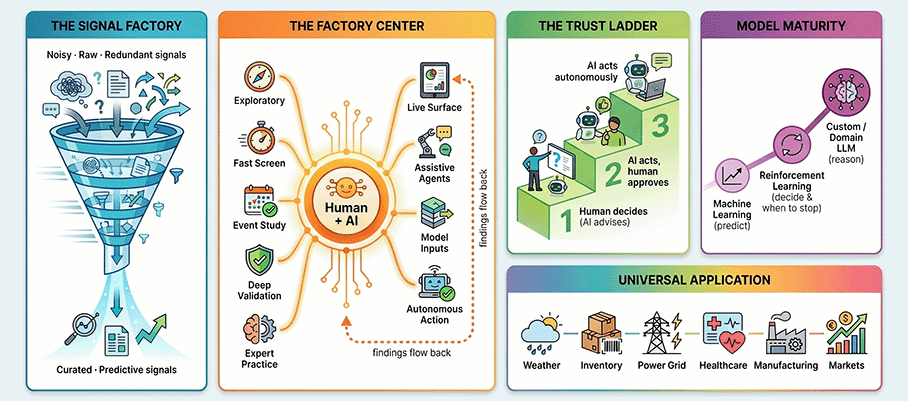
A Factory That Manufactures Validated Signals
The system is best understood not as one application but as a factory: several specialized discovery engines feed a human-plus-AI judgment layer, which feeds several consumers. The engines share results, not a schema — integration happens in the middle, by judgment.
Discovery Engines
Find candidate signals
Human + AI Middle
Synthesize & decide
Live Consumers
Surfaces, agents, the model
Feedback Loop
Outcomes flow back in
And critically: the arrows feeding the consumers also flow backward. Live use and assistive agents aren’t just endpoints — they generate new discoveries that re-enter the factory. The expert’s real decisions surface structural patterns no mechanical search found, which become new hypotheses for the engines and new inputs for the model.
The Discovery Engines
Each engine asks a different question. Together they triangulate signal from independent directions — cheap and fast first, expensive and definitive only for the survivors.
Earn Trust Before Autonomy
The discipline that protects against costly mistakes is a ladder of promotion. A finding climbs from cheap, fast, suggestive tests toward expensive, definitive ones — and toward greater autonomy — only by surviving each step. “Cheap” and “expensive” here mean time, effort, compute, and risk — not money. The point of having several tools is learning speed: triage many candidates fast, spend the definitive effort only on the few that survive.
Human Decides
AI advises
AI Acts
Human approves
AI Acts Alone
Proven — trusted
Two principles govern the ladder: cheap before expensive (a seconds-long check gates an hours-long one) and human before autonomous (a signal must demonstrably help an expert decide better, under real conditions, before it is allowed to act on its own). A signal can be discovered at any step — but it must still climb the rest to be trusted with autonomy.
Letting the Model Grow Up
The far horizon isn’t a single jump to “an autonomous model.” The machine matures through three familiar kinds of model — each one started only when the previous one’s ceiling is proven. Complexity is a cost, not a goal. A smarter model is never automatically a better one — and it never grants itself trust. A custom LLM earns autonomy the same way plain machine learning does: by surviving the ladder.
Most discovery effort points at when to act — the entry, the trigger, the alert. But the real outcome is shaped just as much by when to stop, when to wait, and what not to keep carrying. The cost of holding a decision open past its useful window can quietly erase the value of having acted well.
Every Stage Recalibrates From Reality
Each stage is wrapped in a closed feedback loop — not trained once and frozen. After each decision it observes what actually happened and updates its beliefs, sharpening with evidence. Two rules keep the loop honest: close it on the real-world outcome, not the training proxy (rewarding backtest scores makes a system better at the proxy and worse at the world), and feed calibration back, not just outcomes — over-confidence is its own failure mode.
The Same Method, Any Field
None of this is specific to one domain. The same shape — weak inputs are the bottleneck, cheap engines screen candidates, a human + AI middle judges, a ladder graduates the winners, success is the real outcome — fits any high-stakes prediction problem where being wrong is costly and an expert already does the job.
The fields below are illustrations, not a boundary. The list is open-ended: anywhere a costly outcome can be predicted from signals, the method applies.
| Field | The outcome to predict | What good signals unlock |
|---|---|---|
| Weather / environment | A storm forms, fog lifts, a heat spike | Earlier, more reliable forecasts |
| Data-center capacity | A region runs short of headroom | Smarter build & customer allocation |
| Inventory / supply | A stockout or an overstock | The right amount, in the right place |
| Power grid | A demand ramp or congestion event | Stable, lower-cost dispatch |
| Healthcare (advisory) | A patient begins to deteriorate | Earlier clinician attention |
| Manufacturing | A machine is about to fail | Maintenance before the breakdown |
| Markets | A price moves sharply | Better-timed entries and exits |
| … any field | A costly outcome you can see coming | The same five engines, the same ladder |
When This Method Fits — and When It Doesn’t
The method is not universal. It earns its complexity under a specific shape of problem — and being honest about the boundary is what makes it credible.
| It fits when… | It does not fit when… |
|---|---|
| The outcome is measurable and arrives often enough to learn from | Outcomes are rare, delayed, or unmeasurable — nothing to validate against |
| Being wrong is costly enough that disciplined promotion is worth it | Mistakes are cheap and reversible — just ship fast and fix forward |
| The right signal is non-obvious and context-specific | The relationship is already well-understood and stable — just build the model |
| A human expert already does the task with partial success | There is no human practice to learn from or augment |
| Cheap approximate tests exist to triage before expensive ones | Every test is equally expensive — the ladder loses its leverage |
The pattern is the product — turning human insight into trustworthy AI.
The Discovery Factory.